Na hora de pensar em escalar nossos sistemas, às vezes recorremos ao mecanismo de cache. Infelizmente, nem sempre fazemos uma análise para entender a real necessidade de adicionar um cache em determinado ponto. Então, pensando nisso, vamos ao post de hoje.
Provocações
Quem nunca pronunciou ou já ouviu uma das seguintes frases:
Para evitar bater na API, coloca um cache aqui!
Neste ponto está lento, coloca cache!
Vou disponibilizar uma API e já vou deixar os dados cacheados para ser escalável!
Há ainda uma outra frase bem conhecida no universo de desenvolvimento:
There are only two hard things in Computer Science: cache invalidation and naming things.
– Phil Karlton
Quem já precisou invalidar cache, sabe o peso que essa frase tem em sua vida. Pode parecer uma bobagem, mas já sofri e vi muitas pessoas temerosas na hora de fazer uma faxina no seu servidor de cache distribuído. Já vi sistemas definhando com bugs por causa de dados inválidos em cache. Então, se você ainda não passou por esse perrengue, tome bastante cuidado.
Antes de adicionar cache…
Antes de adicionar cache ao seu sistema, é sempre legal validar aonde está o gargalo, a lentidão ou o ponto a ser melhorado.
Para os sistemas que possuem acesso a uma base de dados, é sempre importante validar se as queries estão seguindo as melhores práticas pensando em performance. Por exemplo, elas estão usando parâmetros em vez de valores fixos nas cláusulas where? Como está o uso dos índices? Já fez alguma análise do plano de execução de alguma query?
Outro ponto importante, é a análise do algoritmo que estamos escrevendo. Quando olhamos nosso código com mais cuidado, ou pedimos para alguém fazer o bom e velho code review, podemos encontrar um código funcional, porém ineficiente. Um exemplo disso é o código poder fazer iterações demais em listas ou alocar muita memória guardando objetos que poderiam ser descartados.
Há ferramentas que podem nos auxiliar nessa empreitada, já escrevi sobre como o PgHero pode nos ajudar a encontrar problemas com as queries que são executadas no PostgreSQL. Também tem um post bem legal no blog do baeldung que nos mostra opções para verificar como está a alocação de recursos na jvm.
Cache Local x Distribuído
Quando decidimos que é hora de adicionar uma camada de cache ao nosso sistema precisamos verificar os trade-offs de usar cache local ou distribuído. Nem sempre é uma decisão simples, mas a única certeza é que uma decisão errada pode comprometer boa parte do seu fluxo apresentando dados inválidos.
Local
Quando decidimos optar pelo cache local, precisamos entender a natureza e o tempo de vida dos dados que serão armazenados. Essa definição é importante para evitar que seu dado fique inconsistente em relação a originador da informação.
Outra preocupação: lembre-se de que o cache local estará consumindo recursos que podem ser importantes em seu sistema, pois ele será armazenado na memória da instância da sua aplicação. Já vi aplicações caindo por falta de memória consumida por cache configurado de forma errada. Cuidado! =)
Além disso, seu sistema pode ter várias instâncias, mesmo que ele seja um monólito, podendo causar inconsistências entre as várias aplicações no ar.
Distribuído
Quando estamos lidando com sistemas distribuídos, utilizar o cache local pode ser um tiro no pé, os motivos já mencionei acima. Parece ser mais fácil adotar sempre o cache distribuído, mas perceba que estamos adicionando um possível ponto único de falha.
Com a utilização do cache distribuído, temos o ganho de ter uma consistência mais forte, pois todas as instâncias da nossa aplicação estarão acessando a mesma base de informação de cache.
Também temos outro ganho, pois otimizamos recursos na adoção de uma única base de cache, como pode ser visto na ilustração a seguir.
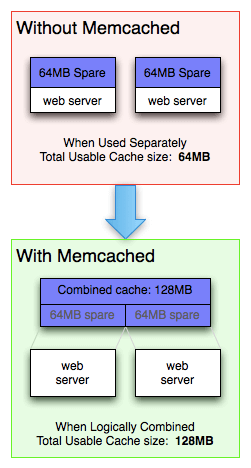 |
|---|
| Fonte: https://memcached.org/about |
Boas práticas
Apesar de usar o Redis como exemplo, algumas das práticas podem ser usadas para qualquer tipo de cache.
- Defina muito bem o Time to live (TTL): uma dica que me ajudou bastante foi entender o comportamento do usuário na aplicação, já consegui reduzir armazenamento de 24h para menos de 8h.
- Utilize chaves curtas, elas também ocupam espaço;
- Para processamentos em lote, o Redis possui o pipeline: já usei esse recurso para repopular o cache com informações novas da base de dados, com isso, reduzimos em quase 90% o tempo de reprocessamento;
- As vezes precisamos iterar uma lista e buscar informações no cache. Use os comandos multiargumentos como o MGET ou MSET;
- Se você possui menos que 4GB de dados que precisam ser armazenados, use a versão de 32bits. Pois os ponteiros terão a metade do tamanho dos de 64bits e alocarão menos memória;
- Sempre que possível use hashes. Chaves possuem metadados, então quanto menos chaves tiver melhor.
Na documentação oficial do Redis tem muito mais dicas sobre otimização de recursos.
E por aí, como foi a sua experiência com cache?
Se curtiu este post não deixe de compartilhar! 😉
Abraços e até a próxima.